Pipelines
With Python, command-line and Jupyter interfaces, ydata-profiling
integrates seamlessly with DAG execution tools like Airflow, Dagster,
Kedro and Prefect, allowing it to easily becomes a building block of
data ingestion and analysis pipelines. Integration with
Dagster or
Prefect can be achieved in a
similar way as with Airflow.
YData Fabric pipelines
Fabric Community version
YData Fabric has a community version that you can start using today to create data workflows with pipelines. Sign up here and start building your pipelines. ydata-profiling is installed by default in all YData images.
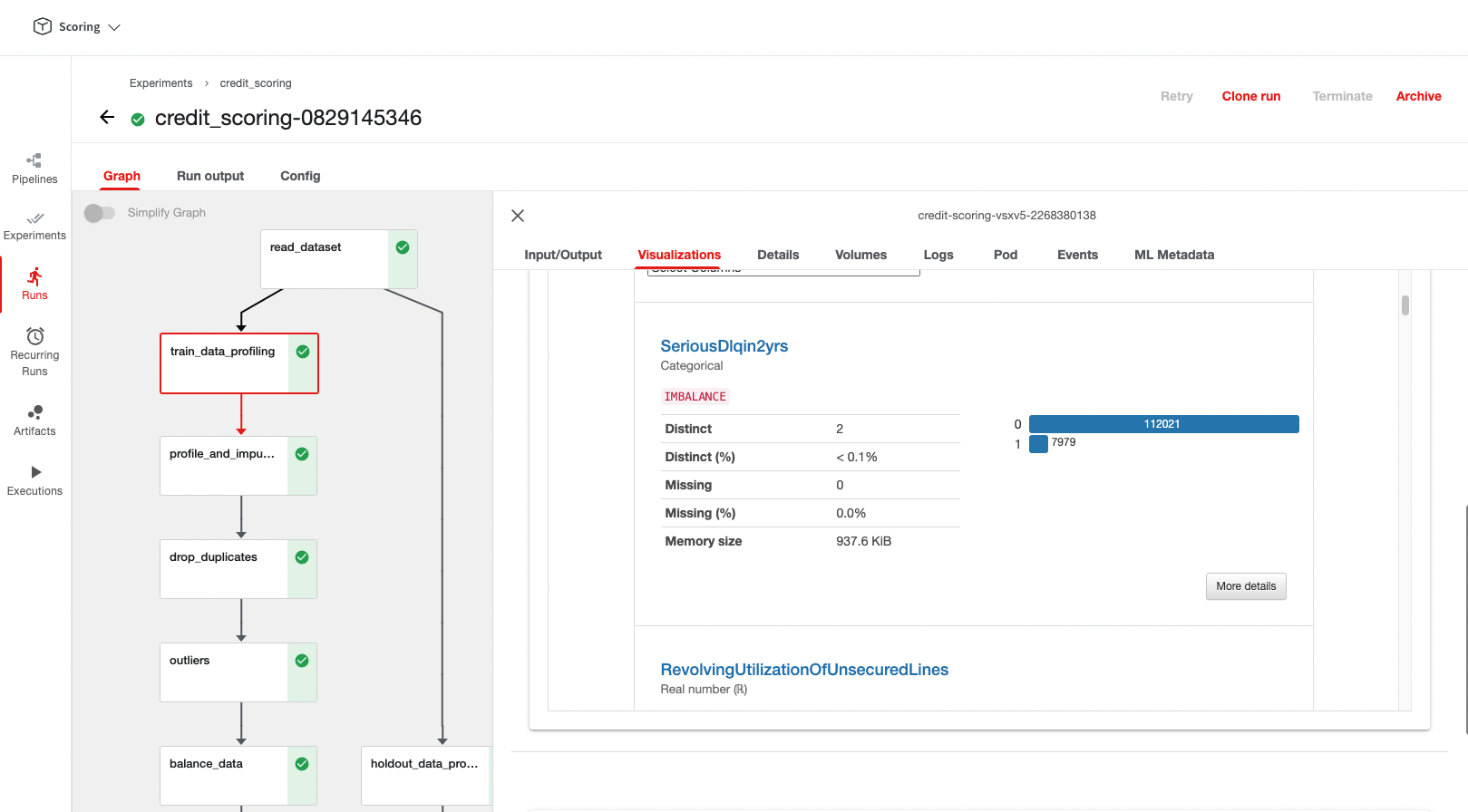
YData Fabric's data pipelines are engineered to harness the capabilities of Kubeflow, providing a robust foundation for scalable and efficient data workflows. This technical integration ensures that data pipelines can seamlessly handle high data volumes and execute operations with optimal resource utilization.
YData Fabric simplifies the process of data pipeline setup by abstracting complexity. The setup is done through a drag-and-drop experience while leveraging existing Jupyter Notebook environments. Check this video to see how to create a pipeline in YData Fabric.
You can find the notebook with this implementation in ydata-profiling examples folder.
Airflow
Integration with Airflow can be easily achieved through the BashOperator or the PythonOperator.
| ydata-profiling with Airflow | |
|---|---|
Kedro
There is a community created Kedro plugin available.
